
操作系统 💻
1.概述
计算机系统是由硬件和软件组成的复杂系统,用于执行各种计算任务和操作。它包括计算机的物理组件(硬件)和执行各种任务的程序(软件)。下面我将介绍计算机系统的工作原理。
- 硬件组件: 计算机系统的硬件组件包括中央处理器(CPU)、内存、存储设备(如硬盘和固态硬盘)、输入设备(如键盘和鼠标)和输出设备(如显示器和打印机)等。这些硬件组件协同工作,以执行各种计算和操作。
中央处理器(CPU)是计算机系统的核心,负责执行指令并处理数据。它包括算术逻辑单元(ALU)和控制单元(CU),ALU执行算术和逻辑运算,CU控制指令的执行顺序和数据的传输。
内存(RAM)用于存储计算机正在执行的程序和数据。程序员可以通过读取和写入内存来操作数据。内存分为不同的层次,包括高速缓存、主内存和辅助存储器(如硬盘)。
存储设备用于长期保存数据,如硬盘和固态硬盘。它们提供了大容量的存储空间,可以持久保存数据,即使计算机关闭也不会丢失。
输入设备允许用户将数据和指令输入计算机系统,如键盘和鼠标。
输出设备用于将计算机处理后的结果显示给用户,如显示器和打印机。
- 软件组件: 计算机系统的软件组件包括操作系统和应用程序。
操作系统是计算机系统的核心软件,负责管理和控制计算机的硬件资源。它提供了一个抽象层,使程序员可以编写应用程序而不必关心底层硬件的细节。操作系统提供了诸如进程管理、内存管理、文件系统和设备驱动程序等功能。
应用程序是由程序员编写的软件,用于执行特定的任务。程序员使用编程语言编写代码,并通过编译或解释器将其转换为计算机可以执行的指令。应用程序可以包括各种类型的软件,如文字处理器、数据库管理系统、图形设计工具等。
计算机系统的工作原理是,当程序员编写代码时,它们被编译或解释为机器语言指令。这些指令由CPU执行,操作系统管理硬件资源,并从内存和存储设备中读取和写入数据。计算机系统通过这种协同工作的方式实现程序的执行,从而完成各种计算任务和操作。
下图所示的 hello 程序来向读者介绍C。尽管 hello 程序是一个非常简单的程序,但是为了完成它的执行,系统的每个主要组成部分都需要协调工作。当你在系统上执行hello 程序时, 系统发生了什么以及为什么会如此运作。
#include <stdio.h>
int main() {
printf("Hello, World!\n");
return 0;
}
通过跟踪 hello 程序的生命周期,它的生命周期从它被程序员创建开始,包括在系统上运行、输出简单的消息,然后终止。我们将沿着这个程序的生命周期,简要地介绍一些逐步出现的关键概念、专业术语和成分。
1.1 位&上下文
hello 程序的生命是从一个源程序(或者说源文件)开始的,该源程序由程序员通过编辑器创建并保存为文本文件,文件名就是 hello.c。 源程序实际上就是一个由0和1组成的位(又称为比特) 序列,这些位被组织成8个一组,称为字节。每个字节都表示程序中某个文本字符。可通过命令 od -t d1 -tcx1 hello.c,查看 hello.c 程序的字节序列。如图1.1:
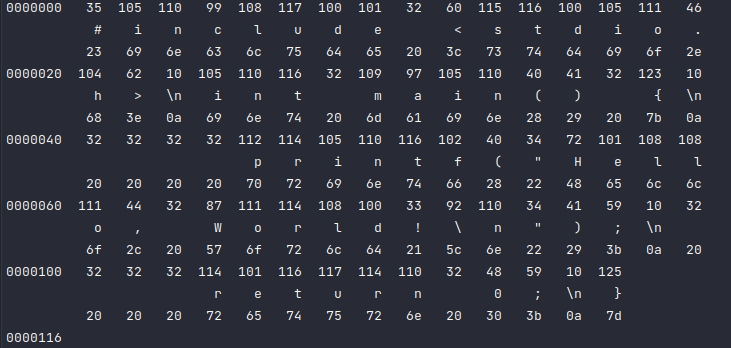
现代系统大部分都使用 ASCII 标准来表示文本字符,这种方式实际上就是用一个惟一的字节大小的整数值来表示每个字符。 hello.c 程序是以字节序列的方式储存在文件中的。每个字节都有一个整数值,对应于某个字符。
hello.c 的表示方法说明了一个基本的思想:系统中所有的信息--包括磁盘文件、存储器中的程序、存储器中存放的用户数据以及网络上传送的数据,都是由一串比特表示的。区分不同数据对象的惟一方法是我们读到这些数据对象时的上下文。比如,在不同的上下文中,同样的字节序列可能表示一个整数、浮点数、字符串或者机器指令。
1.2 源码编译
在 hello 程序生命周期中,开始时是一个高级C程序(源码),当处于这种形式时,它是能够被人读懂的。然而,为了在系统上运行 hello.c 程序,每条C语句都必须被编译器驱动程序 (compiler driver) 编译成一系列的低级机器语言指令。然后这些指令按照一种称为可执行目标程序 (executable object program) 的格式打好包,并以二进制磁盘文件的形式存放起来。
在Unix系统下,一般执行编译的命令是gcc,它会将 hello.c 编译成 hello.o 目标文件。
gcc hello.c -o hello.o
在这里, gcc 编译器驱动程序读取源程序文件 hello.c, 并把它翻译成一个可执行目标文件 hello。这个翻译的过程是分为四个阶段完成的,如图1.2所示。执行这四个阶段的程序(预处理器、编译器、汇编器和链接器)一起构成了编译系统。
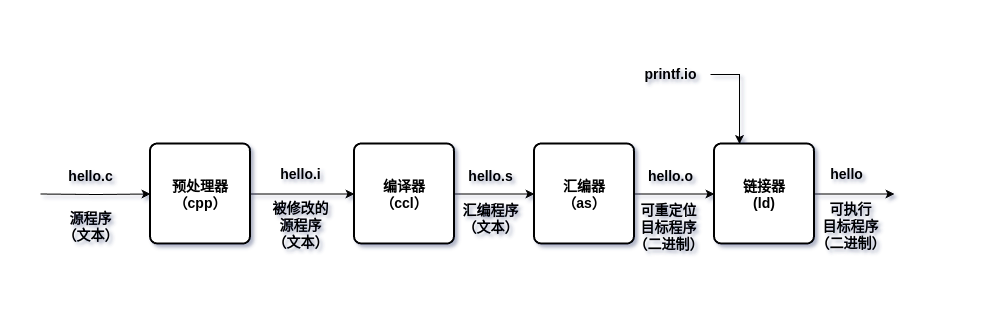
预处理阶段 预处理器(cpp)根据以字符#开头的命令 (directives), 修改原始的C程序。比如 hello.c 中第一行的#include < stdio.h>指令告诉预处理器读取系统头文件 stdio.h 的内容,并把它直接插入到程序文本中去。结果就得到了另一个C程序,通常是以.i作为文件扩展名。
编译阶段 编译器 (ccl)将文本文件 hello.i 翻译成文本文件 hello.s, 它包含一个汇编语言程序。汇编语言程序中的每条语句都以一种标准的文本格式确切地描述了一条低级机器语言指令。汇编语言是非常有用的,因为它为不同高级语言的不同编译器提供了通用的输出语言。例如, C 编译器和 Fortran 编译器产生的输出文件用的都是一样的汇编语言。
汇编阶段 接下来,汇编器(as)将 hello.s 翻译成机器语言指令,把这些指令打包成为一种叫做可重定位 (relocatable) 目标程序的格式,并将结果保存在目标文件 hello.o 中。hello.o文件是一个二进制文件,它的字节编码是机器语言指令而不是字符。如果我们在文本编辑器中打开 hello.o 文件,呈现的将是一堆乱码。
链接阶段 这时,我们的 hello 程序调用了 printf 函数,它是标准C库中的一个函数,每个C编译器都提供。 printf 函数存在于一个名为 printf.o 的单独的预编译目标文件中,而这个文件必须以某种方式并入到我们的 hello.o 程序中。链接器(ld)就负责处理这种并入,结果就得到 hello 文件,它是一个可执行目标文件(或者简称为可执行文件)。可执行文件加载到存储器后,由系统负责执行。
1.3 了解编译系统的益处
编译系统的益处 编译系统的主要目的是优化程序性能。现代编译器都是成熟的工具,通常可以生成很好的代码。作为程序员,我们无须为了写出高效代码而去了解编译器的内部工作。但是,为了在我们的C程序中做出好的代码选择,我们确实需要对汇编语言以及编译器如何将不同的C语句转化为汇编语言有一些基本的了解。比如,一个 switch 语句是不是总是比一系列的 if-then-else 语句高效得多?一个函数调用的代价有多大? while 循环比 do 循环更有效吗?指针引用比数组索引更有效吗?相对于用通过引用传递过来的参数求和,为什么用本地变量求和的循环,其运行就会快得多呢?为什么两个功能相近的循环的运行时间会有很大差异?
理解链接时出现的错误 一些最令人困扰的程序错误往往都与链接器操作有关,尤其是当你试图建立大型的软件系统时。比如,链接器报告说它无法解析一个引用,这是什么意思?静态变量和全周变量的区别是什么?如果你在不同的C文件中定义了名字相同的两个全局变量会发生什么?静态库和动态库的区别是什么?为什么我们在命令行上排列库的顺序是有影响的?最为烦人的是,为什么有些链接错误直到运行时才出现?
避免安全漏洞 缓冲区溢出错误造成了大多数网络和 Internet 服务器上的安全漏洞。这些错误的存在是因为太多的程序员忽视了编译器用来为函数产生代码的堆栈规则。
1.4 处理器工作
hello.c 源程序已经被编译系统转换成了可执行目标文件 hello, 并被存放在磁盘上。为了在 Unix 系统上运行该可执行文件,我们将它的文件名输入到称为 shell 的应用程序中:
unix> ./hello
hello,world
unix>
在 Unix 系统中,shell 是一个非常重要的程序,它是用户与系统进行交互的主要接口。shell 负责执行用户的命令,并将命令的输出返回给用户。shell 是一种命令行解释器,它输出一个提示符,等待你输入一行命令,然后执行这个命令。如果该命令行的第一个单词不是一个内置的 shell 命令,那么 shell 就会假设这是一个可执行文件的名字,要加载和执行该文件。所以在此例中, shell 将加载和执行 hello 程序,然后等待程序终止。hello 程序在屏幕上输出它的信息,然后终止。 shell 随后输出一个提示符,等待下一个输入的命令行。
1.4.1 系统硬件
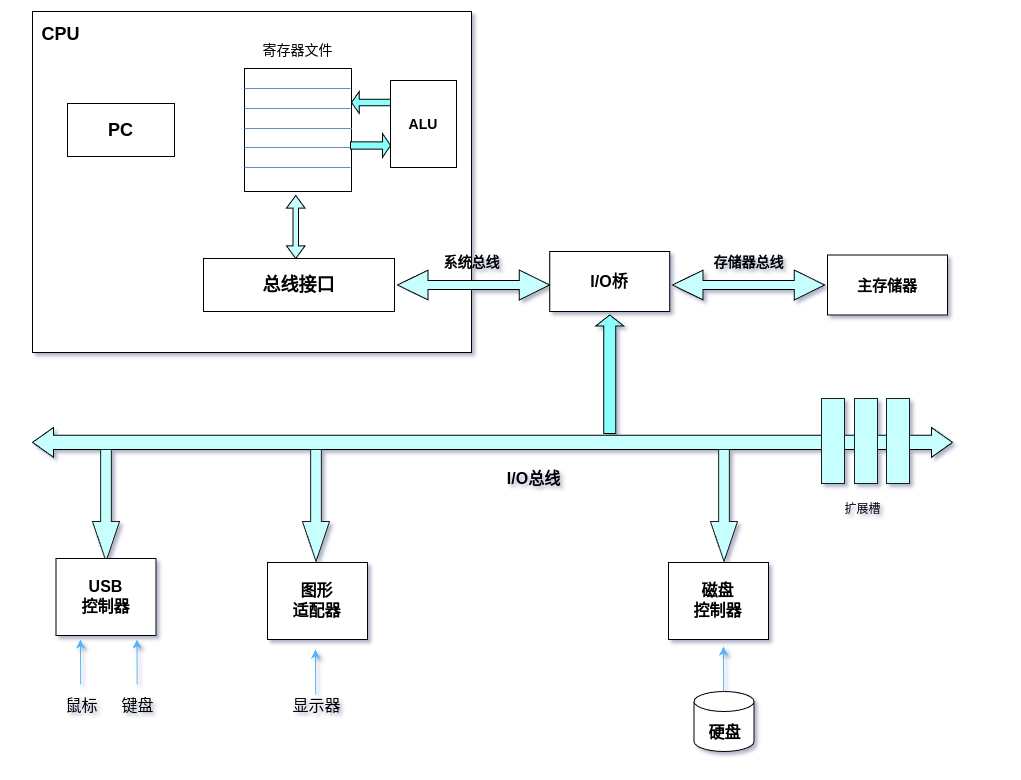
- CPU: 中央处理单元
- ALU: 算术/逻辑单元
- PC:程序计数器
- USB: 通用串行总线
总线
贯穿整个系统的是一组电子管道,称做总线,它携带信息字节并负责在各个部件间传递。通常总线被设计成传送定长的字节块,也就是字 ( word)。字中的字节数(即字长)是一个基本的系统参数,各个系统中也不尽相同。比如, Intel Pentium 系统的字长为4字节,而服务器类的系统,例如 Intel Itaniums和高端的 Sun 公司的 SPARCS 的字长为8字节。
I/O设备
I/O(输入/输出)设备是系统与外界的联系通道。我们的示例系统包括四个 I/O 设备:作为用户输入的键盘和鼠标,作为用户输出的显示器,以及用于长期存储数据和程序的磁盘驱动器(简单地说就是磁盘)。最开始,可执行程序 hello 就放在磁盘上。
每个 I/O 设备都是通过一个控制器或适配器与 I/O总线连接起来的。控制器和适配器之间的区别主要在于它们的组成方式。控制器是 I/O 设备本身中或是系统的主印制电路板(通常被称做主板)上的芯片组,而适配器则是一块插在主板插槽上的卡。无论如何,它们的功能都是在I/O总线和 V/O 设备之间传递信息。
主存
主存是一个临时存储设备,在处理器执行程序时,它被用来存放程序和程序处理的数据。物理上来说,主存是由一组 DRAM ( 动态随机存取存储器)芯片组成的。逻辑上来说,存储器是由一个线性的字节数组组成的,每个字节都有自己惟一的地址(数组索引) ,这些地址是从零开始的。一般来说,组成程序的每条机器指令都由不定量的字节构成。与C程序变量相对应的数据项的大小是根据类型变化的。比如,在运行 Linux 的 Intel 机器上, short 类型的数据需要2字节, int、 float 和 long 类型则需要4字节,而 double 类型需要8字节。
处理器
中央处理单元(CPU)简称处理器,是解释(或执行)存储在主存中指令的引擎。处理器的核心是一个被称为程序计数器(PC) 的字长大小的存储设备(或寄存器)。在任何一个时间点上, PC都指向主存中的某条机器语言指令(内含其地址)。
从系统通电开始,直到系统断电,处理器一直在不假思索地重复执行相同的基本任务:从程序计数器(PC) 指向的存储器处读取指令,解释指令中的位,执行指令指示的简单操作,然后更新程序计数器指向下一条指令,而这条指令并不一定在存储器中和刚刚执行的指令相邻。
这样的简单操作的数目并不多,它们在主存、寄存器文件(register file) 和算术逻辑单元(ALU) 之间循环。寄存器文件是一个小的存储设备,由一些字长大小的寄存器组成,这些寄存器每个都有惟一的名字。 ALU 计算新的数据和地址值。下面是一些简单操作的例子, CPU 在指令的要求下可能会执行这些操作。
加载:从主存拷贝一个字节或者一个字到寄存器,覆盖寄存器原来的内容。
存储:从寄存器拷贝一个字节或者一个字到主存的某个位置,覆盖这个位置上原来的内容。
更新:拷贝两个寄存器的内容到 ALU, ALU 将两个字相加,并将结果存放到一个寄存器中,覆盖该寄存器中原来的内容。
I/O读:从一个 I/O 设备中拷贝一个字节或者一个字到一个寄存器。
I/O写:从一个寄存器中拷贝一个字节或者一个字到一个 I/O设备。
转移:从指令本身中抽取一个字,并将这个字拷贝到程序计数器(PC)中,覆盖PC中原来的值。
1.4.2 执行 hello 程序
通过对系统的硬件组成和操作的简单学习,我们开始能够了解当我们运行示例程序时发生了什么。在这里我们必须忽略很多细节,稍后会做一些补充,但是现在我们将很满意于这种粗略的描述。
首先, shell 程序执行它的指令,等待我们输入命令。当我们在键盘上输入字符串“hello”后, shell 程序就逐一读取字符到寄存器,再把它存放到存储器中,
当我们在键盘上敲回车键时, shell 就知道我们已经结束了命令的输入。然后 shell 执行一系列指令,这些指令将 hello 目标文件中的代码和数据从磁盘拷贝到主存,从而加载 hello 文件。数据包括最终会被输出的字符串“hello, world\n"
利用称为 DMA (直接存储器存取)的技术,数据可以不通过处理器而直接从磁盘到达主存。这个步骤如图所示。
一旦 hello 目标文件中的代码和数据被加载到了存储器,处理器就开始执行 hello 程序的主程序中的机器语言指令。这些指令将“hello, world\n”串中的字节从存储器中拷贝到寄存器文件,再从寄存器中文件拷贝到显示设备,最终显示在屏幕上。